Innovations
July 18, 2024
Innovations: Containing Content Sprawl with AI
Preview the ILINX AI sprawl solution that finds files across systems and repositories, classifies information, and flags unusual content.
We use cookies to help you navigate efficiently and perform certain functions. You will find detailed information about all cookies under each consent category below.
The cookies that are categorized as "Necessary" are stored on your browser as they are essential for enabling the basic functionalities of the site. ...
Necessary cookies are required to enable the basic features of this site, such as providing secure log-in or adjusting your consent preferences. These cookies do not store any personally identifiable data.
Functional cookies help perform certain functionalities like sharing the content of the website on social media platforms, collecting feedback, and other third-party features.
Analytical cookies are used to understand how visitors interact with the website. These cookies help provide information on metrics such as the number of visitors, bounce rate, traffic source, etc.
Performance cookies are used to understand and analyze the key performance indexes of the website which helps in delivering a better user experience for the visitors.
Advertisement cookies are used to provide visitors with customized advertisements based on the pages you visited previously and to analyze the effectiveness of the ad campaigns.
Preview the ILINX AI sprawl solution that finds files across systems and repositories, classifies information, and flags unusual content.
Organizational information is proliferating. When unmanaged information growth results in large numbers of files stored across multiple and unknown locations, we call that “content sprawl.”
Content sprawl affects productivity by making information difficult to locate and act on. It leads to version control issues with users mistakenly generating duplicates and not knowing which file is the most accurate or up-to-date.
These issues are more than an inconvenience; they are also a security hazard. When users take liberties by storing organizational content on their local machines, they may inadvertently expose institutional knowledge or customers’ sensitive information.
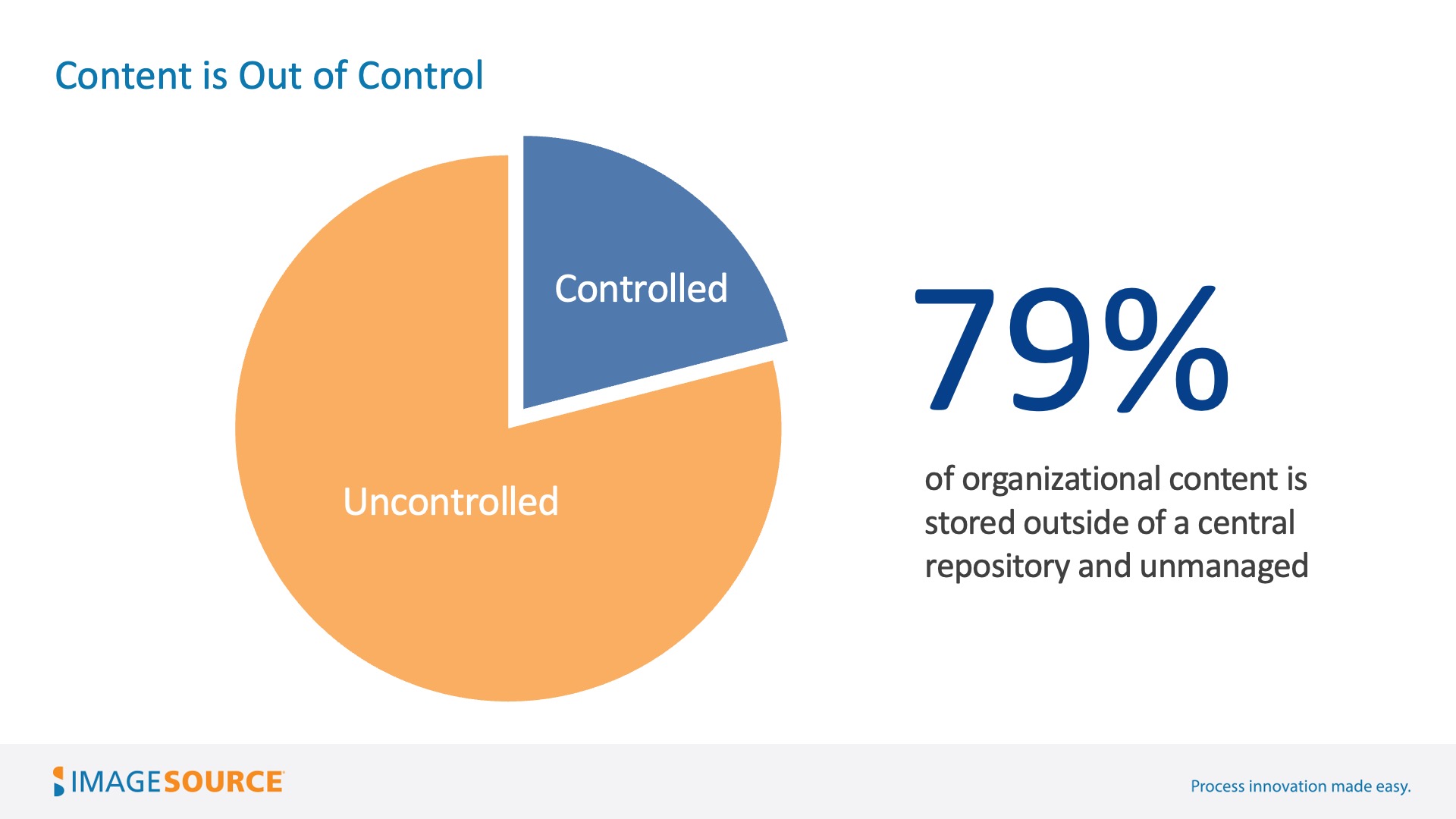
On average, 79% of an organization’s content is unmanaged and stored outside central repositories. Additionally, content is increasing by 25% year over year, 80% of it unstructured. As content sprawls, search values become irrelevant as the search function returns fewer meaningful results.

While some information remains paper-based and some is stored and secured in repositories, today’s content goes beyond traditional documents to include video files, audio files, chat transcripts, and email attachments. A large amount of this information resides in email applications, on OneDrive or SharePoint, personal drives, or on network shares.

ImageSource is working on an AI-driven solution that can point at your content locations across multiple repositories, including OneDrive and SharePoint instances, network shares, and more. This solution automatically classifies the content type, identifies duplicates, and organizes content by age, relevance, and type.
The results provide organizations with a fast way to make data decisions, dedupe, prioritize, and add or revise metadata. Best yet, this solution paves the way to implement organization-wide AI initiatives.

ImageSource’s ILINX solution tackles content sprawl with seven key capabilities:
Data Profiling and Understanding:
Using a combination of supervised and unsupervised AI/ML-based data analysis algorithms, the solution analyzes organizational systems to provide insights into the content and structure of the files within your network shares. It profiles the data to give a comprehensive understanding of what types of documents and data exist, potentially revealing assets that leaders were unaware of.
Data Organization and Clustering:
The ILINX solution automatically clusters content to help identify and group similar types of documents, such as contracts, agreements, and forms. This function can uncover data trends or commonalities that might not be immediately apparent, enabling you to understand how organizational data is distributed across network shares.
Identification of Sensitive Information:
Through its capability to process and recognize patterns in the data, the solution can identify sensitive or personally identifiable information (PII) within your files. This is crucial for compliance with data protection regulations and for securing confidential information.
Document Type Identification:
The solution differentiates and categorizes documents by type without extensive manual input, using machine learning to improve accuracy over time. This means you can quickly identify all instances of specific document types, such as all contracts or financial documents, across systems and network shares.
Novelty and Outlier Detection:
ImageSource’s ILINX solution is designed to detect novelties or outliers in your data, flagging content that deviates from the norm or is unexpected. This feature is vital for identifying anomalies or irregularities, such as unusual or unauthorized file types and content.
Streamlined Data Access and Retrieval:
When applied to organized and categorized data, the solution makes it easier to access, relocate, and retrieve specific types of documents or information. This streamlined access significantly enhances efficiency, especially in large organizations with vast amounts of data.
Insights into Data Evolution:
The feedback loop mechanism allows for continuous improvement of the data model based on new and changing data. This feature provides insights into how your data evolves over time, allowing you to adapt to changes in your business environment and data governance needs.
We’re looking forward to the market launch of our ILINX AI-driven solution to content sprawl solution in fall, 2024. Want to talk with a process innovation expert and get a product preview? Contact us to arrange a conversation.